Short Recap: Dynamic Customer History Segments
In last week’s blog post, a Customer History Segment column was added to the M query for the Customer dimension table of a Power BI dataset. The logic for this column is executed by the source database per refresh to assign each customer row to one of four values (First Year, Second Year, Third Year, Legacy):
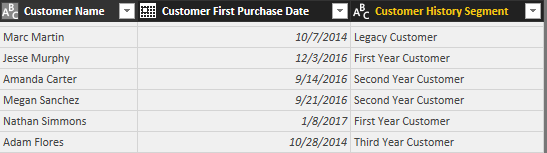
For example, the Alan Zheng customer identified last week was a Third Year Customer at that time but is now a Legacy Customer (over three years) with today’s refresh:

- The new column was well received by users building and consuming Power BI reports and dashboards. (Note: A Power BI dataset designer who writes M queries and DAX measures is a separate role (usually) as described in the Power BI Project Example blog post.)
- The BI/IT organization supported the design since A) the source database was used for executing the entire query and B) they have clear visibility to the logic – both the SQL and the M query.
- We’re going to take this a step further in today’s blog post via Visual Studio and source control integration with Visual Studio Team Services.
New Requirement: Custom Sorting for Segment Column
As a text column, sorting visuals by this column (and not a measure) results in alphabetical order (First, Legacy, Second, Third). The new requirement is to support the logical order (First, Second, Third, Legacy) of the column’s values just like you would with a Weekday column (Mon, Tue,…) or a Month column (Mar, Apr, ).
Sort By Column Implementation
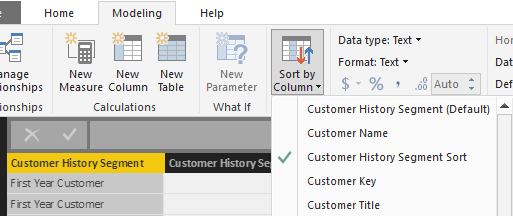
To achieve the Custom Sort from the above image we’ve done the following:
- Add a column to our M query at the same grain of the Customer History Segment column with values that correspond to the intended or logical sort order.
- Set the Sort By Column property of the Customer History Segment to reference this new column.
Additional Requirements
- The revised M query must still exclusively utilize our source database (full query folding, no local M engine resources).
- The revised M query must be tested for performance.
- Once tested, the PQ file should be committed to the team project in Visual Studio Team Services.
The Results First
The new column stores an integer value associated with each of the four text values of the Customer History Segment column:
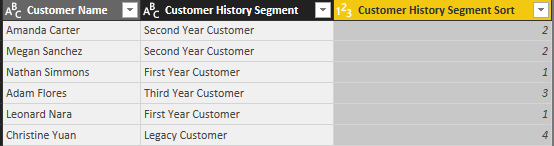
Customer History Segment column sorted by the new integer column (Segment Sort):
Revised M Query in Visual Studio
Here’s the revised Customer PQ file in Visual Studio 2017:
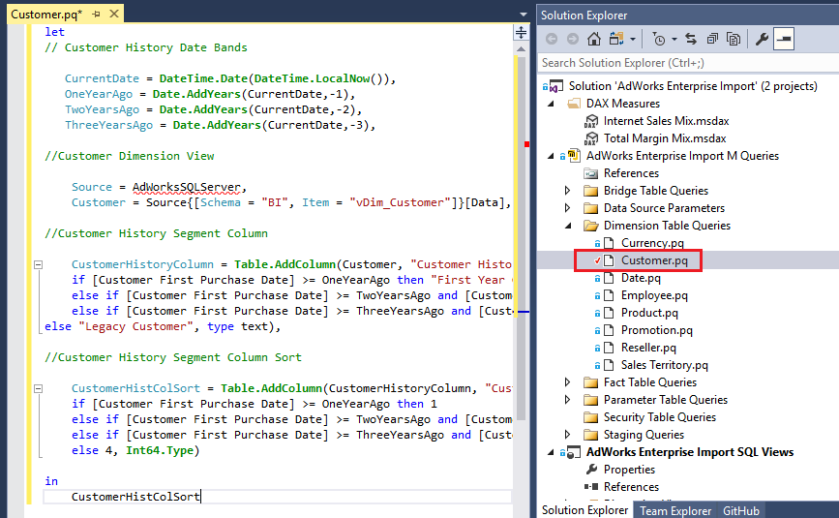
The new column (CustomerHistColSort variable) leverages the same date variables and conditional logic expression created in the previous blog post but sets a whole number data type (Int64.Type). You always want to declare the data type of the column created within the Table.AddColumn() function. If you don’t, you’ll get an ‘Any’ or unknown data type that will result in a text column when loaded to the data model.
Note: The new M variable ‘could’ simply reference the Customer History Segment Column (e.g. if “Second Year Customer” then 2) but that would result in a less efficient SQL query. Specifically, derived table would be created rather than a single SELECT statement. Performance testing of T-SQL queries is outside the scope of this blog post but the point is that query folding alone isn’t sufficient – you need to be sensitive to the form and performance of the SQL query being generated from the M expression.
- The Power Query SDK for Visual Studio is described in this recent blog post.
- You should hide the Customer History Segment Sort column from the Report View (Fields list) as it’s only purpose is to support the sorting.
Committed M Queries
The committed changes from the PQ solution in Visual Studio are now visible in the Power BI team project in VSTS:

- Version control can be applied on the Power BI Desktop file itself via OneDrive for Business.
- At the moment (obviously) we don’t have colorization support for M queries in VSTS as we do with Visual Studio and Visual Studio Code.
- Sets of (.pq) files (M queries) built into the familiar Visual Studio solution and source control environment (ie TFS, VSTS) can benefit projects and longer term deployments of Power BI in many ways.
- You may notice I’m using MSDAX files and the SQL views as well – this likely deserves its own blog post.
Wrapping Up: Technical Debt??
If it’s necessary to frequently create and modify lengthy M queries you probably have data warehouse and architecture issues that should be addressed (at some point). In a future stage or ‘sprint’, for example, you might remove the custom M columns as these are now included in the data warehouse and supported via an ETL tool and process.
Once the customer dimension is revised in the data warehouse you could be in a position to once again temporarily extend your BI architecture via M queries (in SSAS too) if necessary. Every organization is different but my view is to try to set a hard limit on these customizations and consistently migrate the logic upstream such that you’re not constantly taking on more and more custom M queries as a substitute for a sound data warehouse.
Feel welcome to leave comments or thoughts though I may not be available to reply for several days.

One comment