The Power BI Professional’s Guide to Azure Synapse Analytics, a white paper I wrote describing the Synapse Analytics platform and its benefits and use cases for Power BI professionals, was published a couple weeks ago. This post discusses a few themes from this paper and also shares a couple notes that weren’t included.
Balanced Architecture: Performance
A performant and scalable data warehouse such as a provisioned SQL pool resource in Azure Synapse Analytics can be combined with Power BI modeling features such as aggregation tables and composite models. The business intelligence team or solution architect can choose to leverage Power BI Premium capacity, specifically its available RAM resources, to deliver optimal performance for common and high priority BI queries, which typically reflect higher level groupings/aggregations, while allowing the SQL pool resource to resolve more granular queries. Power BI datasets (semantic models) containing both cached/in-memory aggregation tables as well as DirectQuery tables will likely become the generally accepted or recommended architecture for enterprise-grade models built over large data warehouses.
Alternatively, the BI team could choose to keep all tables in the Power BI model in DirectQuery storage mode thus avoiding any additional data movement/copy activities outside the data warehouse and possible synchronization issues between the DW and Power BI refresh/load timings. Historically, DirectQuery has been challenging from a performance perspective in general and was even identified as an anti-pattern for SQL DW years ago. However, performance advancements in the data warehouse layer such as materialized views, result set caching, and ordered columnstore indexes as well as in Power BI such as aggregation tables, query caching and improved query folding can make DirectQuery performance at scale acceptable for many workloads.
The all DirectQuery approach would be appropriate for organizations with policies which forbid the copy/data movement associated with import mode storage tables in Power BI models. Additionally, organizations with strong data warehouse teams which actively implement and manage the performance of Synapse SQL in partnership with the Power BI teams such as via the performance tuning features previously mentioned as well as with statistics and index maintenance, and performance monitoring tools may also prefer this approach. (Suboptimal data warehouse practices such as a unnecessarily large data types and insufficient maintenance of columnstore indexes would naturally lead the BI team to rely on in-memory tables to deliver performance)
If performance issues are reported for a DirectQuery dataset, one of the very first things to check is whether the model uses any aggregation tables, either cached or in DirectQuery storage mode. One aggregation table and/or perhaps one materialized view in Synapse SQL that persists the complex logic and joins of a source SQL query can completely change the performance profile of a Power BI dataset.
Balanced Architecture: Security
In many BI environments which reflect significant investments in Analysis Services on-premises servers (SSAS) or Azure Analysis Services resources, or perhaps large in-memory Power BI datasets, data security is the responsibility of the semantic model rather than the source data warehouse. End users are merely mapped to row-level security roles such that DAX filters are applied to their sessions – their identity and connection is exclusive to the Analysis Services instance.
With Synapse Analytics, it’s possible to pass the user’s identity from Power BI to Synapse SQL and allow Synapse to apply its row-level security (RLS) and optionally other security policies.
In addition to RLS, Synapse supports column-level security and dynamic data masking such that granular security logic can be applied to all Power BI datasets and other applications using Synapse SQL as its data source.
Although BI teams strive to avoid the proliferation and duplication of data models, it’s not uncommon for several data models to be supported by IT for various reasons such as the scope of past projects or the past scalability limits with Power BI datasets. By implementing security in Synapse, it’s no longer necessary to duplicate and manage RLS security logic across these semantic models or, more fundamentally, ensure that Power BI developers have effectively and efficiently implemented in Power BI models. Additionally, any Power BI paginated reports which use Synapse as a direct source via T-SQL queries, can leverage the same Synapse security rather than implementing any custom application-level security approach.
Security can also become a shared responsibility between Synapse SQL and Power BI datasets. For example, RLS security policies in Synapse could ensure the Power BI user only sees a particular Country while an RLS role in the Power BI dataset could further limit the user to a particular product category. To avoid performance degradation of Synapse SQL due to complex security logic as well as to further the goal of rapid and flexible BI delivery, organizations may choose to implement their most basic and essential RLS logic in Synapse while allowing BI developers/architects to implement the custom security logic required for their projects.
Performance OR Security??
Synapse has a rich and growing set of performance and security features, several of which are inherited from Azure SQL DW. However, currently, there are real limitations when you try to combine the newer performance features with the data security features. This effectively means that you have to either forego your preferred architecture such as not implementing RLS in Synapse in order to deliver performance or invest more in your data warehouse such as with a higher service level objective or additional development (e.g. more tables to support) to deliver the same results.
Specifically, materialized views and result set caching simply don’t work with row-level security policies. If you try to create a materialized view on top of a table which happens to have a security policy, you’ll get an error message like this:
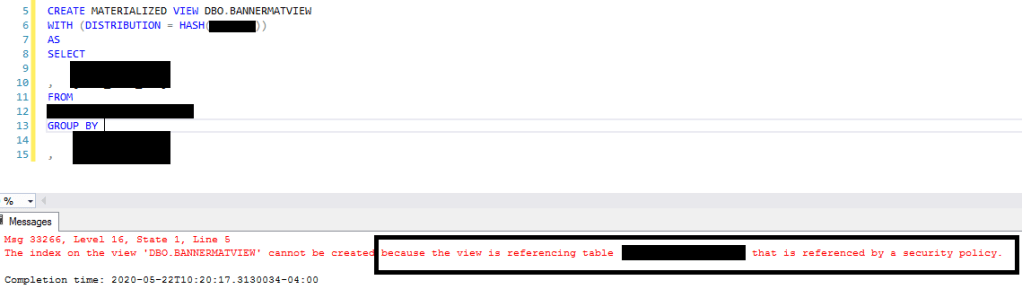
Likewise, if you were hoping that result set caching would minimize your query workload and deliver good user experiences in Power BI due to repeating queries, just read the section ‘What’s not cached’ on the result set caching doc page:

The white paper and presentations on Synapse with Power BI discuss and demonstrate these performance and security features leaving the impression that you’re free to use them without any conflict – this simply isn’t true. Moreover, I’m not aware of any timeline of a planned enhancement that would allow you to use result set caching or materialized views with your security policies.
If you’re committed to implementing data security policies in Synapse (as many organizations are or will be), you’ll need to maximize other available performance features such as the ordered columnstore index and be very thoughtful about other design decisions such as table distributions and resource classes.
The Age of the Full Stack BI Developer
One ongoing trend which I believe both Synapse and Power BI contributes to is the replacement of tool-specific BI experts with full stack developers. The full stack developers are not gurus in any one technology such as Azure Data Factory pipelines or writing Spark notebooks or T-SQL scripts or DAX metrics but they’re skilled in a wide assortment of these tools and they understand their relationships. The integration of these different technologies within Synapse (see Synapse Studio) and its several linked services makes it increasingly feasible and more cost-effective and productive to empower a small group of full stack developers from a centrally managed team to build solutions. This contrasts greatly with traditional tool-specific roles such as the report developer, the BI modeler, the ETL developer, etc which are often separated across different teams.
The full stack BI developers enjoy the same simple advantages that a self-service BI analyst has in Power BI – they have knowledge of the full set of requirements and they possess clear visibility and control over many or all aspects of the solution. For example they know why a change in a T-SQL stored procedure should be made given its implications for a Power BI dataset or report because they’re very close to both artifacts. There will probably always will be certain areas where supplementing full stack BI developers with tool-specific gurus could be desirable or necessary and determining how much competence/skill is necessary in any one tool can be tricky. These details aside, the overall trend is that we’re heading toward the age of full stack BI developers.
Notice what Amanda Silver, CVP of Product for Microsoft’s Developer Division, said earlier this year regarding Visual Studio: “We’ve seen increasing speed of new technologies coming out…this means developers don’t have the time to get really deep in the technology they’re learning…And so what we need to do is ensure developers can become polyglots (know multiple languages) but deploy quickly into whatever domains they need to develop for.”
The first slide, though focused on application developers rather than BI developers, definitely (in my view) applies to BI:

Wrapping Up
Thanks for visiting Insight Quest and I hope you found this post and, if you downloaded it, the new white paper useful. Upcoming blog posts may go deeper into composite models, columnstore index analysis tools, paginated report development techniques (not sure yet) so just subscribe if you want to receive an email notification.

2 comments