This post reviews the deployment of common changes to Power BI datasets and the implications for the availability of the affected objects for users and reports. BI teams and owners of PBI datasets can use these examples to plan out deployments and, if necessary, coordinate with other stakeholders such as data engineers and report authors.
Why This Matters
A breaking change, which we can define as any change to a dataset which causes either reports to render errors or the dataset to fail to refresh, can severely impact business workflows and reflect poorly on those responsible for the solution. Given significant investments in other areas of the organization’s data estate such as Azure Synapse Analytics, a simple, easily avoidable oversight in a Power BI deployment may not be tolerated.
Tools and Prerequisites
Primary tools for these examples are Power BI Desktop for dataset changes, a Power BI Premium workspace, and ALM Toolkit for deploying changes from PBI Desktop to Power BI Premium. Of course, given support for the XMLA endpoint, other tools such as Tabular Editor, PowerShell, and SQL Server Management Studio can be applicable to the deployment and processing of changes in datasets.
If you’re not using ALM Toolkit for deploying dataset changes, perhaps because the PBI dataset is small and has no partitions or incremental refresh (or just because it’s easier to click ‘Publish’ in PBI Desktop), I’d still recommend ALM Toolkit. This tool alone will call out the variances between the source and target dataset, gives the option to select which variances/changes to deploy, and comes with built-in validation checks to help prevent breaking changes.
Obviously a test environment and CICD process for deploying dataset changes from Test to Production would reduce the risk of breaking changes. Setting up and using these processes may be the subject of a future post. This post assumes the model owner/author manually deploys metadata changes to the production dataset, perhaps after the given changes/development have been approved or validated via a Test dataset.
Measures
Changes to measures are probably the most common type of dataset change and thus it’s important to distinguish the type of measure changes which result in errors (breaking changes) versus those that don’t.
- Measure Name Change
- Yes, changing the name of a measure will result in errors in reports that reference the old measure name.
- Therefore, measure name changes such as the adoption of a particular naming convention, should be communicated and planned advance with report authors.
- To avoid a disruption to production reports, one option is to create a new measure rather than rename an existing measure. Report authors would be given time to modify their reports to use the new measure and then, once the dependency on the old measure is eliminated, it can be deleted from the dataset.
- Yes, changing the name of a measure will result in errors in reports that reference the old measure name.
- Measure Home Table Change
- Yes, changing the home table of a measure will result in errors in reports that reference the measure.
- For example, changing the home table of the Distinct Products Sold measure from Internet Sales to Product (or a dedicated Metrics table) would result in errors in reports referencing this measure.


Measure Display Folder Change
- No, adding or modifying the display folder of measures will not result in breaking changes.
- Provided the home table of the measure doesn’t change, any new/revised displayed folder will not impact reports.
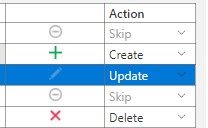
If you’re using ALM Tookit for deploying measure changes, you’ll notice that measure name changes and home table changes result in Create and Delete actions while display folder changes result in Update actions. This is one simple indication of which changes can be a breaking change.
Columns
The process for adding and removing columns from PBI datasets can trip teams up as the dataset can become out-of-sync with it’s source. This can result in a new column not being exposed to users, a new column being exposed but having no values/data, or a dataset refresh failure due to a missing column.
Adding a column
Let’s assume the intent is to add a column (attribute) to the Product dimension table. The data engineering table will add the column to the Product dimension table in the data warehouse and add select the new column in the view object(BI.vDim_Product) accessed by the Power Query (M) expression in the PBI dataset:
let
Source = Sql.Database(Server, Database),
ProductView = Source{[Schema="BI",Item="vDim_Product"]}[Data]
in
ProductViewHaving a single view object per table in a PBI dataset is a recommended practice. Additionally, using parameters for values like a server name and database name make it possible to modify the data source of a deployed dataset. Examples of scripts to modify dataset parameters will be covered in Common PBI Admin Scripts Part III.
An inexperienced team may be tempted to think that the new attribute in the source database will automatically be added to the deployed Power BI dataset during its next refresh process. Perhaps this will be the behavior at some point in the future but it’s not true today. Today, it’s necessary to follow this process:
- Add the column in the local PBI dataset
- Refresh the Product table in PBI Desktop and observe the new attribute.
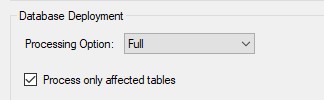
- Set the Database Deployment Option in ALM Toolkit to Process Full and Process only affected tables
- Validate and Update in ALM Toolkit to both A) revise the metadata of the Product dimension table and B) Process the Product table
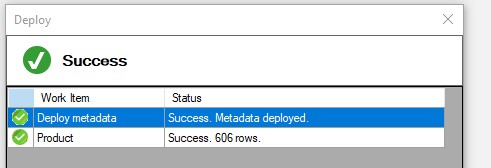
If the Processing Option in ALM Toolkit was set to Do Not Process, the new attribute would be added to the dataset but it would be empty until the table is processed again. Thus, if users may be expected to access the new column prior to the next refresh, it would be necessary to execute a process operation on the Product table either via the GUI interface in SSMS or a PowerShell script such as the following snippet:
Invoke-ProcessTable -TableName 'Product' -RefreshType Full -Server $Workspace
-DatabaseName $Dataset -Credential $PSCredThe above uses the SqlServer module (imported from Windows PowerShell) in PowerShell 7. The post on XMLA-based dataset refreshes offers more detail on this.
Removing a Column
Removing a column requires the dataset schema to be modified just like adding a column. Power BI is not going to change its dataset schema on the fly to align to the source – it’s going to throw an error indicating the column it was expecting but didn’t find like the example below:
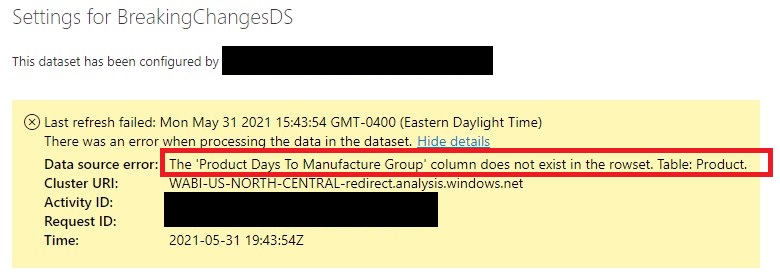
To avoid a dataset refresh failure (and thus stale data for users/reports), dataset owners and the data source team should coordinate such that an updated dataset schema is deployed to reflect the removal of the column(s). Owners of the data source should never add or remove columns to the view objects used by the PBI dataset without communicating/planning this change with the PBI dataset owners.
Additionally, PBI dataset owners should identify and address any dependencies on the columns to be removed. In the following example from Tabular Editor, it’s found that a DAX measure (Online Sales ($) is dependent on the Unit Price column:

In this case, an alternative but equivalent DAX expression that doesn’t reference the Unit Price column would need to be applied to the Online Sales ($) metric to avoid a breaking change.
Relationships
Relationships have their own structures internal to the PBI dataset that need to be calculated to avoid breaking changes.
For example, let’s say that it’s determined that the active relationship between Internet Sales fact table and the Date dimension table should be changed from Order Date to Due Date. If this is implemented via a metadata-only deployment from ALM Toolkit, without any further operation the users will get an error like the following:
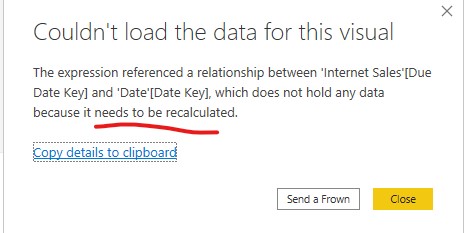
Adding a recalculate operation to the deployment of the revised relationship will avoid the breaking change per the following images:


Adding a Recalc computes the derived structures (relationships, hierarchies, calculated columns and tables) that need to be calculated given the state of the object. As an alternative to including recalc in the deployment from ALM Toolkit, you could execute a process recalc via the SSMS graphical interface or via PowerShell (SqlServer module) immediately following the metadata deployment like the following snippet:
Invoke-ProcessASDatabase -Server $Workspace -DatabaseName $Dataset
-RefreshType Calculate -Credential $PSCredLike relationships, creating and changing hierarchies also requires a process calculate.
Wrapping Up
As valuable as the many Power BI analysis and visualization features are, the availability of Power BI datasets (ie avoiding breaking changes) is foundational to many of these experiences. BI developers and teams responsible for deploying changes to Power BI datasets can use this blog post and other resources to plan and deploy dataset changes that avoid or minimize the impact on report authors and users of the dataset.
Thanks for visiting Insight Quest. If interested in receiving email notification of future blog posts, you can follow this blog via the Subscribe widget on the right-hand side of the home page.

Thanks for the insights, Brett! I am getting more and more familiar with ALM Toolkit and this provides me with some good pointers.
LikeLike
Nice post thanks ffor sharing
LikeLike