The Scenario: The New Application is Slow
Last week I helped tune a client’s SSAS Tabular (Import Mode) DAX queries that are used for a new web application to improve response time and user experience. To prove that the DAX queries were at least a large part of the performance problem (not the app, not hardware) and that optimization was a feasible and meaningful undertaking, we chose one of the more painful queries and I took about 3-4 hours re-designing it and testing for improvement.
DAX Query Tuning Results: It’s The Code


Per the images from DAX Studio above, after several structural changes to the DAX query, query duration dropped from 57 to 4.6 seconds with the number of storage engine queries coming down from 83 to 17.
As mentioned, this was one of the more painful queries so other queries may not benefit as much from the changes but as you can imagine these results are very encouraging.
Note: Nothing in the data model (SSAS Tabular) or hardware was touched, just the query.
Why this happened?
Nothing fancy. The revised query simply implemented the following two techniques:
- Apply the filtering parameters (from the web app in this case) to the root (inner) table to be queried; outer metrics are then evaluated against the pre-filtered table
- Leverage the inner query result set for additional groupings/totals required; avoid querying the storage engine for the same data twice
The Original (Slow) Query Structure

It may look fairly harmless to some of you. How could such a simple query cause such a problem for SSAS Tabular (2014 in this case)?
The Revised (Fast) Query Structure
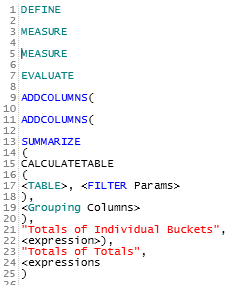
The new query was indeed much ‘longer’ than the original in terms of characters and functions and appears more complex but it isn’t at all once you walk through it.
DAX expressions are evaluated from the inside to the outside functions (with one exception). The inner expression for the original query returns an entire table since FILTER is outside of SUMMARIZE. Metrics were being evaluated for all the rows of this unfiltered table (ie computing sales for all your customers, not just the customers requested by the user). The original query isn’t filtered until the very end, when it’s too late – the high price in terms of queries to the storage engine has already been paid.
The revised query eliminates the FILTER function with a CALCULATETABLE and inserts it into the table parameter of the SUMMARIZE function. Thus, before SUMMARIZE applies it’s grouping/projecting, and well before the metrics are evaluated, a small result set has been returned reflecting the user selections. The fact table is scanned only for these rows.
The second important component at work here is the use of ADDCOLUMNS. *ADDCOLUMNS is an iterator like FILTER so you only want to use it on small or pre-aggregated sets of data. In this example, the application was asking for several different buckets such as product category A, B, C. The total of these values was also required and then a grand total was required to consolidate two subtotals. The original query was ‘double dipping’ – it was using metrics (hitting the storage engine) for both the individual buckets and the required subtotals and grand totals.
In the revised query, the first ADDCOLUMNS applied all the metrics defined prior to the EVALUATE, outside of pre-filtered SUMMARIZE, and then this table was passed to the second ADDCOLUMNS which simply added the results together to provide the subtotal and total columns – easy computations on the few rows returned by the query.
*Defining measures that are scoped locally to the query and referencing them in ADDCOLUMNS is recommended as an alternative to using the third parameter to SUMMARIZE.
**Notice how the % of time spent in the storage engine shot up to 97%. That’s almost always a good sign – that means you’re only using the single threaded formula engine to operate on a tiny dataset, you’re letting the multi-threaded xVelocity engine handle the heavy work.
So two simple questions you might ask with your DAX queries (for SSRS or any other client app in which you can define the DAX ) are “Am I applying the most selective filter first/early?” and B) “Am I querying for the same data more than once?”
I only have 60 minutes at Boston Code Camp but I’ll definitely be touching on DAX as a query language, especially given the new query functions available (SUMMARIZECOLUMNS) and the modernized SSRS 2016.
Note: I didn’t have time this week to review all the new October Power BI Desktop features so this will get pushed to next week.

Thank you!!!!
LikeLike