SSAS Tabular 2017 Partitions
Incremental data refresh is not yet available to support large Power BI datasets. It’s on the Power BI Premium Roadmap, but, even with incremental refresh and future support for very large datasets (1TB – 5TB), there will still be very good reasons to choose SSAS for IT-managed, corporate BI solutions. A few of these reasons include perspectives, drillthrough expressions, display folders, object level security, built-in source control integration, and full administrative controls and programmatic capabilities (ie TMSL, TOM).
Without going further into that conversation (PBI Dataset vs. SSAS Model), let’s walk through one method for building partitions into an SSAS Tabular 2017 model (1400 compatibility level).
Tabular Project Setup
The essential steps to reach a starting point for defining partitions in a Tabular model are included in the 7-image slideshow below. This includes creating a new Tabular project in SSDT at the 1400 compatibility level, connecting to a data source (SQL Server in this case), and selecting a view object representing the fact table to be partitioned.
The starting point for this post is after clicking ‘OK’ from the Navigator for the SQL view – this will launch the query editor.
Fact Table Expressions
Staging Query
- Right-click the query and disable the Create New Table property.
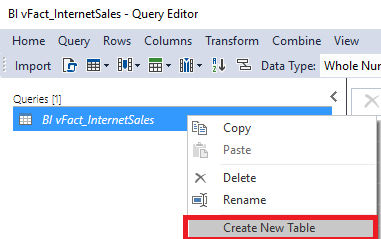
- Rename the query ‘InternetSalesStg’.
- The partitions will reference this query.
- You can optionally view the M query generated by clicking the Advanced Editor icon (script image, next to Import).
- It will look similar to the data source staging queries reviewed in this blog post (Source{[Schema=”BI”,Item=”vFact_InternetSales”]}[Data]).
Fact Table Partition Load
- From the same right-click menu, duplicate the InternetSalesStg query.
- Rename the duplicated query ‘Internet Sales’.
- Enable the Create New Table property for this query.
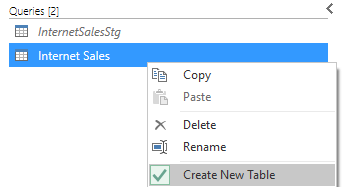
Just like Power BI, the expression that’s not loaded to the model has a gray font.
- For the Internet Sales query, click the Advanced Editor icon (next to Import).
- Set the source variable equal to the InternetSalesStg query.
- Add a variable with the Table.SelectRows() function to only retrieve one month of data (or optionally a sample partition size).
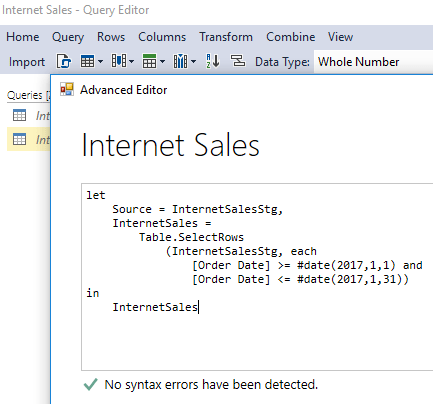
- Click Done to close out of the Advanced Editor.
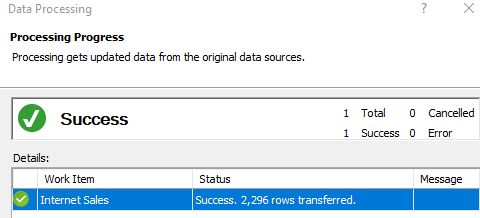
- Click Import to create the Internet Sales table in the model and load the single month of data.
Creating Partitions
For this example, the January 2017 rows of the Internet Sales table are now loaded to the workspace model:
- Now open up the Partition Manager interface in SSDT.
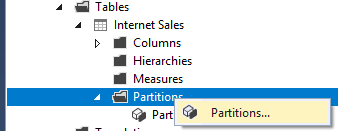
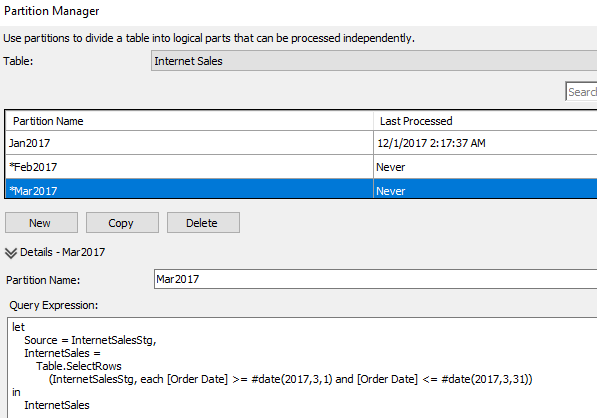
- Change the partition name to Jan2017.
- Click copy to create additional partitions based on the same query.
- Revise the queries (Table.SelectRows()) and the names for each partition.
Deploy for Testing
With the deployment processing option set to ‘Do Not Process’, go ahead and deploy the model to the server to test the partitions.
- In SSMS, open up the partition processing window for the fact table.
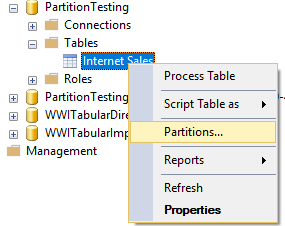
- Process a few of the partitions with a trace running against the source database.
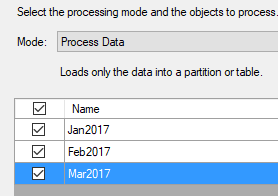
Note: Parallel partition processing was added in SSAS Tabular 2016.
The SQL statement associated with each partition will be visible from the trace:

Per the WHERE clause, this SQL statement was executed to support the processing of the March 2017 partition. The view object originally referenced by the staging query (BI.vFact_InternetSales) is in the FROM clause.
Wrapping Up
Per the introduction, there are other ways of handling partitions in Tabular 2017 such as with M functions or with SQL statements. The main idea is that each partition simply calls the staging query and applies a filter. Therefore, changes to the SQL view referenced by the staging query or the staging query itself will flow to the partitions.
Next week’s blog will either look at 1-2 of the recent report authoring features for Power BI or some DAX query language use cases (ie SSRS to SSAS). We may also briefly follow up on this post and look at changing the structure of the fact table such as adding or removing columns to the partitioned fact table.
Insight Quest Update
Today’s three blog posts (see Relative Date Filters, Waterfall Chart) pushed us over 100 all time blog posts. It seems like yesterday that the first post was published (the song is Awake by Tycho, by the way). I look forward to the next 100 blog posts – click the subscribe link if interested. Also, I’ve added a few details to the on-site training page.

One comment